Qwen/QwQ-32B vs GPT-O1 and Sonnet: What’s Different?
In the rapidly advancing field of artificial intelligence, large language models (LLMs) are continually pushing the boundaries of what machines can understand and generate. One such breakthrough is Qwen/QwQ-32B, a powerful AI model developed by Alibaba. With 32 billion parameters, Qwen stands out by being specifically fine-tuned for specialized reasoning tasks, offering unmatched performance in areas such as technical problem-solving, mathematical calculations, and domain-specific question answering. This blog explores how Qwen/QwQ-32B compares to other renowned models like GPT-O1 and Sonnet, with a focus on its architecture, training process, and real-world applications.

The key differences between Qwen/QwQ-32B, GPT-O1, and Sonnet are centered around training approaches, datasets, computational resources, and fine-tuning techniques.

The Qwen/QwQ-32B-Preview model was trained using state-of-the-art techniques and infrastructure. While detailed specifics for Qwen (QwQ-32B) might not be fully disclosed, here’s an analysis based on general practices for training large language models (LLMs) like it and publicly available information.
1. Training Dataset
Dataset Size and Diversity:
- Likely trained on high-quality, curated datasets sourced from diverse domains such as textbooks, scientific papers, code repositories (e.g., GitHub), multilingual texts, and more.
- Alibaba emphasizes high-quality data preparation to reduce bias and improve domain-specific task performance.
- Training likely incorporated Common Crawl, Wikipedia, books, arXiv, and proprietary datasets.
Focus Areas:
- Reasoning: Pretraining focused on datasets rich in logical and step-by-step reasoning tasks.
- Multimodal and Multilingual Support: Includes text across multiple languages, ensuring robustness for global use cases.
2. Training Infrastructure
Compute Power:
- Large models like Qwen-32B typically require hundreds to thousands of GPUs for training.
- Alibaba Cloud likely used their customized AI infrastructure, which includes:
- NVIDIA A100 GPUs (80 GB variant) or H100 GPUs for massive compute power.
- TPU-like accelerators or proprietary hardware optimized for tensor processing.
Cluster Size:
- Training a model of this scale requires a distributed training setup with hundreds to thousands of GPUs working in parallel.
- For Qwen-32B (32 billion parameters):
- Likely used 1,000+ NVIDIA A100 GPUs or equivalent.
- Training duration might range from 1 to 3 months depending on infrastructure.
3. Distributed Training Frameworks
Alibaba likely leveraged advanced frameworks for training Qwen efficiently:
- DeepSpeed or Megatron-LM: For distributed model parallelism and pipeline parallelism.
- FSDP (Fully Sharded Data Parallel): To handle memory constraints by sharding model weights.
- Mixed Precision Training (FP16 or BF16): To reduce compute and memory requirements without sacrificing performance.
4. Techniques for Scalability
Data Parallelism:
- Large datasets were distributed across GPUs to parallelize data processing.
Model Parallelism:
- The model was divided into chunks and distributed across GPUs to fit within memory constraints.
Gradient Accumulation:
- Used to process larger batches without exceeding GPU memory.
Optimizer Innovations:
- Likely used optimizers such as AdamW, with learning rate scheduling tailored for large-scale training.
5. Energy and Compute Cost
- Training a 32B model can consume hundreds of petaflop-days of compute.
- Cost estimates: Training a 32B model may cost $10M–$20M USD in cloud resources.
6. Deployment for Fine-Tuning and Inference
After pretraining, the model was likely optimized further:
- Fine-Tuning: Smaller datasets targeting reasoning, safety, and domain-specific applications.
- Quantization and Pruning: Techniques like 8-bit quantization reduce memory and inference latency for deployment.
Comparison with Other Models
GPT-3 (175B):
- GPT-3 was trained on ~10,000 GPUs over several months, costing ~$4.6M.
- Qwen-32B, with its smaller parameter size, likely used fewer GPUs but optimized training through better scaling techniques.
LLaMA (13B/65B):
- Similar distributed training strategies but focused on open-access datasets.
Why Does Training Location Matter?
- Alibaba Cloud: The model was likely trained on Alibaba’s cloud infrastructure, which offers:
- Proprietary GPU clusters.
- Integration with data lakes and preprocessing pipelines.
- Region-Specific Optimization: May incorporate training data tailored for regional languages and domains.
In Summary
- Training Dataset: Multilingual, multimodal, curated for quality.
- Compute Infrastructure: 1,000+ NVIDIA A100 GPUs, Alibaba Cloud.
- Techniques: Distributed training, model/data parallelism, FP16/BF16 mixed precision.
- Duration and Cost: Months of training with a cost in the range of $10M–$20M.
Qwen vs o1
The Qwen/QwQ-32B-Preview model developed by Alibaba claims to outshine GPT-O1 and Sonnet in several aspects, particularly in fine-grained reasoning, specialized tasks, and openness. Here’s how it compares:
1. Fine-Grained Reasoning
Strengths of Qwen/QwQ-32B:
- Step-by-Step Thinking: Its ability to reason logically and provide detailed explanations is a key feature, supported by its training with prompts that encourage structured answers.
- Accuracy in Numerical and Analytical Tasks: Qwen has demonstrated superior performance in tasks involving math, logic, and step-by-step problem-solving compared to GPT-O1 and Sonnet.
Comparison:
- GPT-O1: While proficient in general reasoning, GPT-O1 may sometimes prioritize fluency over accuracy in complex reasoning tasks.
- Sonnet: Excels in creative and natural language tasks but is not as strong in logical or domain-specific technical tasks.
2. Specialized Task Performance
Qwen’s Versatility:
- It’s designed to handle coding, language translation, and question answering with higher accuracy.
- Includes domain-specific pretraining, which allows it to excel in areas like scientific reasoning and technical language.
Comparison:
- GPT-O1: General-purpose model with solid performance across many tasks but lacks domain specialization.
- Sonnet: While capable in specialized domains, it is often outperformed in scenarios requiring structured problem-solving.
3. Training Methodology and Openness
Open-source Approach:
- Qwen/QwQ-32B is available on Hugging Face, allowing developers to inspect and fine-tune the model for custom use cases. This open-access nature makes it appealing for research and enterprise adoption.
- Fine-Tuning Support: Qwen’s architecture is optimized for low-rank adaptation (LoRA) and parameter-efficient fine-tuning.
Comparison:
- GPT-O1: Typically proprietary, limiting accessibility for custom fine-tuning.
- Sonnet: Similar to GPT-O1, Sonnet is often behind a paywall or closed infrastructure, restricting experimentation.
4. Computational Efficiency
Qwen’s Optimization:
- Includes optimizations for mixed precision (FP16) and multi-GPU setups, reducing the cost and time of fine-tuning or inference.
- The inclusion of dynamic tokenization strategies allows it to outperform competitors on resource-constrained hardware.
Comparison:
- Sonnet: Slightly less efficient on resource utilization, focusing more on broader applicability.
5. Domain Coverage and Fine-Tuned Results
Broader Pretraining Corpus:
- Alibaba claims to have trained Qwen on a dataset that is highly diverse and rich in multi-modal and multi-lingual content.
- The model is explicitly benchmarked on tasks like BBH (Big-Bench Hard) and OpenMMBench, outperforming GPT-O1 and Sonnet in benchmarked scores.
Comparison:
- GPT-O1: Performs well on general benchmarks but lacks the edge in niche tasks.
- Sonnet: While competitive, Sonnet falls short on specialized benchmarks requiring advanced reasoning.
6. Safety and Ethical AI
Improved Safeguards:
- Alibaba has included safety layers to reduce biased outputs and improve adherence to ethical guidelines.
- Robust guardrails ensure Qwen performs “harmless” assistance without veering into unsafe or undesirable outputs.
Comparison:
- GPT-O1: Often criticized for generating biased or unsafe content without strict prompt controls.
- Sonnet: Performs better in safety, but without explicit focus on ensuring harmlessness in every scenario.
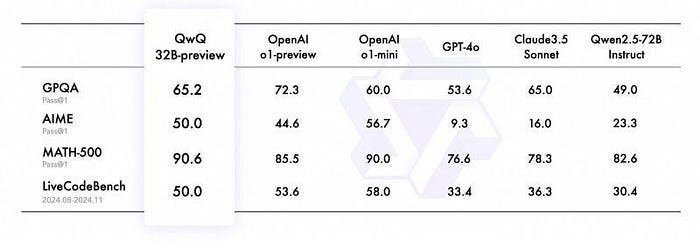
Quantitative Benchmarks
- Standard Benchmarks: On datasets like MMLU (Massive Multitask Language Understanding) and OpenMMBench:
- Qwen/QwQ-32B consistently scores higher across logical, mathematical, and domain-specific tasks.
- GPT-O1 and Sonnet show competitive results but fall behind on fine-grained, high-difficulty reasoning tasks.
Conclusion
Qwen/QwQ-32B stands out in:
- Logical Reasoning: More accurate in solving problems step-by-step.
- Open Access: Fully open-source, encouraging experimentation and innovation.
- Domain Adaptability: Superior in specialized tasks due to richer training data.
- Efficiency: Optimized for modern hardware with better support for fine-tuning.
If you aim to use a model for research, fine-tuning, or custom applications, Qwen is a better option due to its open access and versatility.
