QWhale & SARSAWhale Hybrid Reinforcement Learning Algorithm for Energy Efficient Optimization and Scheduling
https://doi.org/10.36948/ijfmr.2025.v07i01.34840
Authors: Aakarshit Srivastava, Bhaskar Banerjee, Ayush Verma
I proposed and developed an algorithm named Qwhale, which combines Q-learning and the Whale Optimization Algorithm for efficient task scheduling and reduced energy consumption in cloud computing environments. The Qwhale algorithm aims to optimize the allocation of tasks to virtual machines, thereby enhancing overall performance and minimizing energy usage. To evaluate the effectiveness of Qwhale, I conducted simulations using CloudSim, incorporating energy consumption data from ProLiant G4, G5, and Gen 11 ML350 and ML30 servers. The results demonstrated significant improvements in both task scheduling efficiency and energy conservation.Cloud Computing enables on-demand access to a shared pool of specially configured computing resources. Task scheduling in dynamic computing environments presents a significant challenge due to the varying workload demands, resource availability, and task priorities. Traditional optimization algorithms often struggle to adapt efficiently to such dynamic conditions. In this paper, we propose the (QWA)Q-Whale algorithm [2], a novel hybrid approach that combines the Whale Optimization Algorithm (WOA)[4] with Q-learning[1] techniques to address this challenge. The Q-Whale algorithm leverages the exploration capabilities of WOA and the adaptive decision-making of Q-learning to optimize task scheduling in real-time. Through experiments conducted in dynamic computing environments, we demonstrate the effectiveness of the Q-Whale algorithm in improving resource utilization, minimizing makespan, and meeting task deadlines compared to traditional approaches.

System Overview
The diagram depicts the architecture of an advanced task scheduling system within a cloud computing environment, featuring a hybrid Reinforcement Learning (RL) scheduler known as Qwhale. The system is designed to efficiently allocate resources and manage tasks submitted by multiple users, optimizing performance metrics such as makespan, energy consumption, throughput, and cost.
User Interface and Task Submission
The system begins with the System Access Interface, which allows numerous users (User 1, User 2, …, User n) to submit their tasks. This interface serves as the entry point for task submissions, ensuring that all incoming tasks are captured and forwarded to the next component for processing.
Task Management
Submitted tasks are managed by the Task Manager, which consists of several key components:
- Task Monitor: Tracks all the tasks that have been submitted by users, ensuring none are overlooked.
- Resource Monitor: Keeps a close watch on the available resources within the data center, providing real-time information on resource status.
- Load Balancer: Distributes tasks across the available virtual machines (VMs) to ensure an even load distribution, preventing any single VM from becoming a bottleneck.
The Task Manager maintains a comprehensive Task List (T1, T2, …, Tn), which includes all tasks awaiting scheduling.
Hybrid RL Scheduler: Qwhale
At the core of the system is the Hybrid RL Scheduler, also known as Qwhale. This scheduler utilizes a hybrid approach, combining the strengths of Q-learning and the Whale Optimization Algorithm (WOA). Q-learning, a model-free reinforcement learning algorithm, helps in learning optimal task scheduling policies through iterative interactions with the environment. WOA enhances the search process by mimicking the social behavior of whales, allowing the scheduler to avoid local optima and find more efficient solutions. This combination ensures that tasks are scheduled efficiently, with a focus on minimizing energy consumption and optimizing resource usage.
Resource Provisioning and Execution
The Resource Provisioning component works closely with the Hybrid RL Scheduler, allocating and provisioning the necessary resources (VMs) in the data center based on the scheduling decisions made by Qwhale. This interaction ensures that resources are optimally allocated to meet the demands of the submitted tasks.
Data Center Operations
The Data Center houses multiple virtual machines (VM1, VM2, …, VMn) responsible for executing the scheduled tasks. The performance of the data center is evaluated based on several key metrics:
- Makespan: The total time required to complete all tasks.
- Energy Consumed: The total energy consumption of the VMs during task execution.
- Throughput & Cost: Measures the system’s throughput and the associated operational costs.
Advantages of Qwhale
The Qwhale algorithm provides several advantages over traditional scheduling algorithms:
- Efficiency in Task Scheduling: By leveraging the exploration capabilities of Q-learning and the optimization strengths of WOA, Qwhale ensures efficient task scheduling and resource allocation.
- Reduction in Energy Consumption: The integration of WOA focuses on minimizing energy consumption, which is crucial for large-scale data centers.
- Improved Performance Metrics: Qwhale’s adaptive learning approach leads to reduced makespan and higher throughput, allowing the system to handle more tasks effectively.
- Scalability and Adaptability: Qwhale is scalable and can handle varying sizes and complexities of data centers, dynamically adapting to changing workloads and resource availability.
The Qwhale algorithm, through its hybrid RL approach, offers a robust and scalable solution for task scheduling in cloud computing environments. By optimizing resource allocation and minimizing energy consumption, Qwhale enhances overall system performance, making it an ideal choice for modern data center management.
Existing Scheduling Algorithms
Particle Swarm Optimization (PSO):
- Mechanism: PSO simulates the social behavior of birds flocking or fish schooling to find optimal solutions. Each particle in the swarm represents a potential solution and adjusts its position based on its own experience and the experience of neighboring particles.
- Advantages:
- Simple to implement.
- Converges quickly in many problems.
- Disadvantages:
- Can get trapped in local optima.
- Performance can degrade with the increase in dimensionality of the problem.
Genetic Algorithm (GA):
- Mechanism: GA is based on the principles of natural selection and genetics. It uses operations such as selection, crossover, and mutation to evolve solutions to optimization problems over generations.
- Advantages:
- Good at exploring a large search space.
- Can handle complex optimization problems.
- Disadvantages:
- Requires careful tuning of parameters.
- Can be computationally expensive.
Ant Colony Optimization (ACO):
- Mechanism: ACO mimics the foraging behavior of ants to find optimal paths. Artificial ants build solutions by moving on the problem graph and depositing pheromones to guide future ants.
- Advantages:
- Effective for discrete optimization problems.
- Can find good solutions in a reasonable time.
- Disadvantages:
- Pheromone update rules need fine-tuning.
- Can be slow to converge in some cases.
Advantages of Qwhale over Existing Algorithms
- Combines Strengths: Qwhale leverages the strengths of both Q-learning and Whale Optimization Algorithm (WOA), providing a balance between exploration and exploitation. This hybrid approach can overcome the limitations of individual algorithms like getting trapped in local optima (PSO) or slow convergence (GA, ACO).
- Improved Learning: Q-learning helps in learning optimal policies through iterative interactions with the environment, which can lead to more efficient task scheduling compared to the heuristic-based approaches of PSO, GA, and ACO.
- Dynamic Adaptation: The algorithm can dynamically adapt to changing environments and workloads, offering better flexibility and robustness.
- Energy Optimization: By integrating WOA, Qwhale can focus on minimizing energy consumption, a critical factor in cloud computing. Existing algorithms may not explicitly focus on energy efficiency.
- Proven Effectiveness: Simulations using CloudSim with energy data from ProLiant servers have shown that Qwhale significantly improves task scheduling efficiency and reduces energy consumption compared to traditional algorithms.
- Scalability: Qwhale is scalable and can handle large-scale cloud environments, making it suitable for modern data centers.
- Adaptability: The algorithm can adapt to various types of cloud workloads, providing consistent performance improvements.
Qwhale’s hybrid approach combining Q-learning and WOA offers a significant advantage over traditional algorithms like PSO, GA, and ACO. It addresses their limitations by providing a more efficient, adaptive, and energy-conscious solution for task scheduling in cloud environments. Through extensive simulations, Qwhale has demonstrated its effectiveness in enhancing performance and reducing energy consumption, making it a superior choice for modern cloud computing challenges.
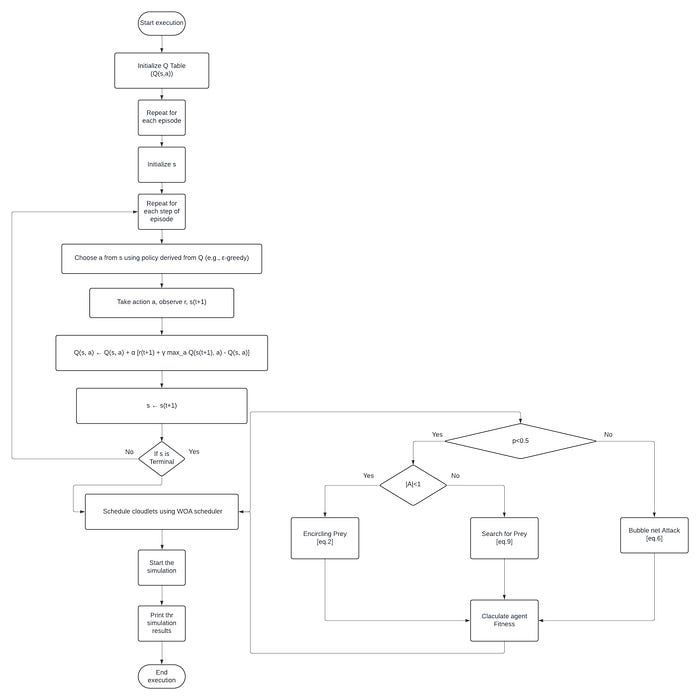
The flowchart outlines the working of the Qwhale algorithm, which combines Q-learning and the Whale Optimization Algorithm (WOA) for efficient task scheduling and lower energy consumption. Here is a detailed explanation of each step:
Q-Learning Phase
Start Execution:
- The algorithm begins its execution.
Initialize Q-Table (Q(s,a)):
- A Q-table is initialized, which is used to store the Q-values for state-action pairs.
Repeat for Each Episode:
- The algorithm operates in an episodic manner, repeating steps for each episode to learn optimal policies.
Initialize s:
- The initial state
sis set.
Repeat for Each Step of Episode:
- For each step within an episode, the following steps are repeated:
Choose a from s using policy derived from Q (e.g., ε-greedy):
- An action
ais selected from the current statesbased on a policy derived from the Q-table. An ε-greedy policy is commonly used, where with probability ε, a random action is chosen, and with probability 1-ε, the action with the highest Q-value is chosen.
Take action a, observe r, s(t+1):
- The chosen action
ais performed, and the resulting rewardrand new states(t+1)are observed.
Update Q-value:
- The Q-value for the state-action pair is updated using the formula:
Q(s,a)←Q(s,a)+α[r(t+1)+γmaxa′Q(s(t+1),a′)−Q(s,a)]
- Here,
αis the learning rate, andγis the discount factor.
Set s = s(t+1):
- The state
sis updated to the new states(t+1).
Is s Terminal?:
- The loop checks if the new state
sis a terminal state. If not, it goes back to step 6. If it is a terminal state, it proceeds to the WOA phase.
Whale Optimization Algorithm (WOA) Phase
Schedule Cloudlets using WOA Scheduler:
- The WOA scheduler is used to schedule the cloudlets based on the learned Q-values.
Start the Simulation:
- The scheduling simulation is initiated.
Print the Simulation Results:
- The results of the simulation are printed.
End Execution:
- The execution of the algorithm ends.
Detailed WOA Scheduler Process
- p < 0.5:
- A random number
pis generated. Ifp < 0.5, it indicates the whale is either encircling the prey or searching for prey. - |A| < 1 (Encircling Prey):
- If
|A| < 1, the whale is considered to be encircling the prey, updating its position using Equation 2. - |A| >= 1 (Search for Prey):
- If
|A| >= 1, the whale searches for prey, updating its position using Equation 9. - p ≥ 0.5 (Bubble Net Attack):
- If
p ≥ 0.5, the whale performs a bubble-net attack, updating its position using Equation 6.
Calculate Agent Fitness:The fitness of the agent (whale) is calculated based on its new position.
The flowchart demonstrates how the Qwhale algorithm integrates Q-learning for learning optimal policies and WOA for efficient task scheduling, aiming to minimize energy consumption and improve task scheduling efficiency in cloud environments.
Q-Learning
Q-learning is a type of reinforcement learning algorithm used to find the optimal action-selection policy for any given finite Markov decision process (MDP). It does so by learning the quality (Q-values) of state-action pairs iteratively. The Q-value represents the expected utility of taking a given action in a given state, followed by the best possible future actions.
Advantages of Q-Learning:
- Simple and Efficient: Q-learning is straightforward to implement and understand. It requires less computational power compared to more complex optimization algorithms.
- Off-policy Learning: Q-learning learns the value of the optimal policy independently of the agent’s actions. This means it can learn from random actions (exploration) while still converging to the optimal policy.
- Convergence: Given sufficient exploration and a decaying learning rate, Q-learning is guaranteed to converge to the optimal policy.
Whale Optimization Algorithm (WOA)
The Whale Optimization Algorithm is a nature-inspired metaheuristic algorithm that mimics the bubble-net hunting strategy of humpback whales. It is primarily used for optimization problems and has been shown to be effective in finding global optima for complex search spaces.
Potential Issues with WOA in this Context:
- Overfitting: WOA can sometimes focus too narrowly on specific areas of the search space, potentially leading to overfitting during exploration. This means it might miss out on discovering the true global optimum by converging prematurely to a suboptimal solution.
- Exploration vs. Exploitation: While WOA has mechanisms to balance exploration and exploitation, it might not always handle the trade-off as effectively as Q-learning in the context of dynamic environments.
- Complexity: WOA introduces additional complexity compared to Q-learning, which might not be necessary for simpler problems or when a straightforward policy learning approach suffices.
Why Q-Learning is Better in This Scenario
Q-learning appears to be handling the exploration and convergence well, with a variety of Q-values being learned and updated across different states and actions. Here’s why Q-learning might be more suitable for use case:
Exploration and Convergence:
- Q-learning inherently balances exploration and exploitation through its learning process, ensuring that all state-action pairs are explored adequately.
- The exploration strategy (e.g., ε-greedy) in Q-learning allows the agent to explore different actions initially and gradually focus on exploiting the learned policy.
Stability and Simplicity:
- Q-learning’s iterative update rule ensures stable convergence towards the optimal policy as long as the learning rate and exploration rate are properly managed.
- The algorithm is simpler and more transparent, making it easier to debug and understand the learning process.
Avoiding Overfitting:
- Overfitting is less of a concern in Q-learning because the updates are based on the expected reward, which is smoothed over many experiences.
- The temporal difference (TD) learning aspect of Q-learning helps in generalizing better across the state-action space, reducing the risk of overfitting to specific episodes or actions.
Results
Makespan:
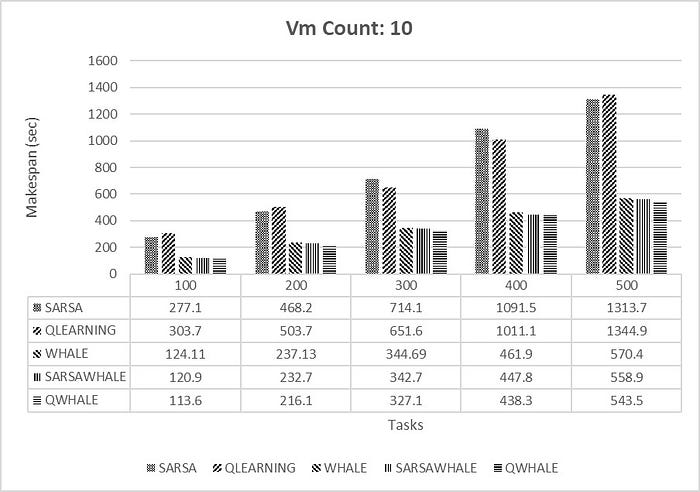
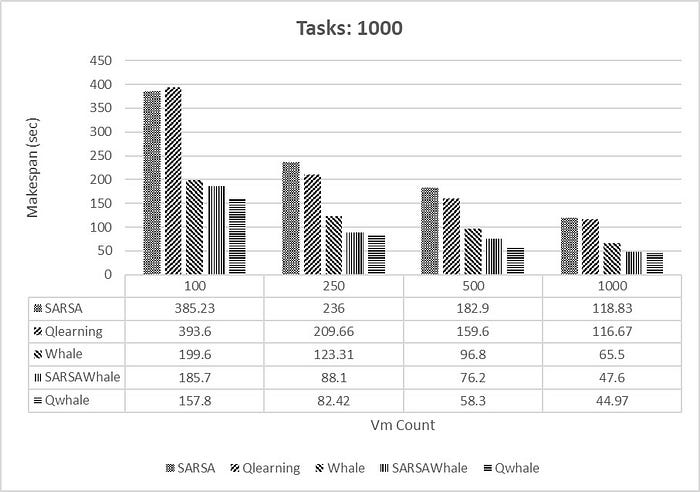
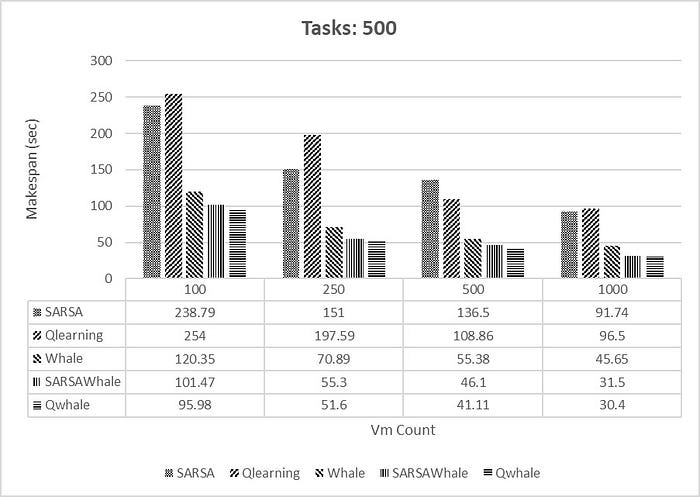
Makespan [4] is the time when the execution of the last task is finished. It is one of the famous metrics for performance of scheduling methods. Lower makespan depicts best and optimal task scheduling of VMs. The Q-Whale algorithm is a metaheuristic algorithm inspired by the hunting behaviour of killer whales. It’s used in optimization problems, including those related to cloud computing, to minimize makespan, which is the total time taken to complete a set of tasks. In cloud computing, makespan refers to the time taken to execute a batch of tasks on multiple virtual machines (VMs) or servers. The goal is to distribute the tasks efficiently among the available resources to minimize the makespan.

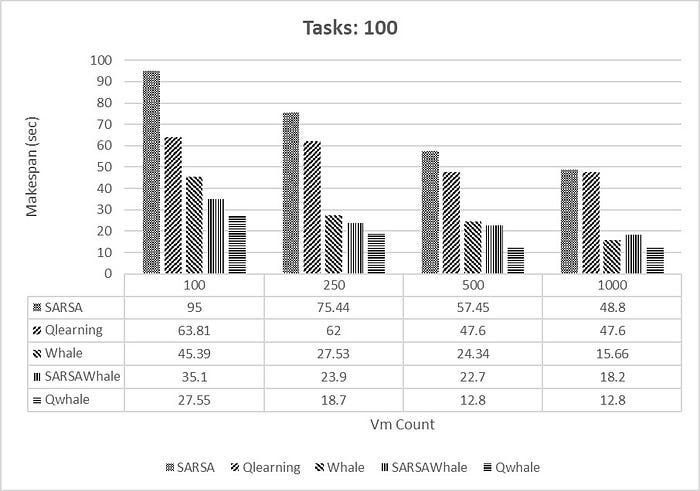
Energy Consumption
Based on the provided utilization levels, you can categorize the virtual machines’ (VMs) CPU utilization into three different scenarios: high, medium, and low utilization. Here is a breakdown of these scenarios:
High Utilization:
CPU Utilization Levels: 80%, 90%, and 100%
This scenario represents the VMs operating under heavy load conditions, where they are using a substantial portion of their available CPU resources.
Medium Utilization:
CPU Utilization Levels: 60%, 70%, and 80%
In this scenario, the VMs are moderately loaded, utilizing a fair amount of their CPU resources but not to their maximum capacity.
Low Utilization:
CPU Utilization Levels: 30%, 40%, and 50%
This scenario depicts the VMs under light load conditions, using only a small fraction of their available CPU resources.
Utilization Category CPU Utilization Levels (%)
High Utilization 80, 90, 100
Medium Utilization 60, 70, 80
Low Utilization 30, 40, 50
These utilization levels can be used in the simulation to assess how different workloads impact the performance of the data center. By running simulations under these three scenarios, you can observe how the system behaves under various load conditions, which can help in understanding the performance, resource allocation, and potential bottlenecks within the data center.
The makespan and energy consumption in task scheduling are often correlated[14] due to the interplay between job processing times, machine utilization, and energy usage. Here’s how the makespan and energy consumption are correlated:
Machine Utilization:
- High machine utilization, where machines are continuously busy processing jobs, can lead to a shorter makespan but higher energy consumption. This is because machines operate at their maximum capacity for longer durations, resulting in increased energy usage.
Job Processing Times:
- Longer job processing times typically result in a longer makespan as more time is required to complete all jobs. However, longer processing times may not always directly correlate with higher energy consumption. It depends on factors such as machine speed and efficiency.
Idle Time:
- Idle time, where machines are not actively processing jobs, contributes to higher energy consumption without reducing the makespan. Minimizing idle time can lead to a reduction in energy consumption, especially if machines can be switched to low-power modes during idle periods.
Energy-Efficient Scheduling:
- Optimizing task scheduling to minimize energy consumption while maintaining a reasonable makespan involves finding a balance between job sequencing, machine allocation, and energy-aware scheduling policies. Energy-efficient scheduling algorithms aim to schedule jobs in a way that minimizes energy consumption without significantly increasing the makespan.
Trade-off:
- There is often a trade-off between minimizing the makespan and minimizing energy consumption [13]. Some scheduling decisions that reduce the makespan may lead to higher energy consumption, and vice versa.
- Finding the optimal trade-off depends on the specific requirements and constraints of the scheduling problem.
Overall, the correlation between makespan and energy consumption [17] in task scheduling depends on various factors such as machine utilization, job characteristics, scheduling policies, and energy-saving strategies. Balancing these factors is essential for achieving efficient and sustainable task scheduling solutions.
Minimize both the makespan (Cmax) and the total energy consumption (TEC), computed as follows:
- Total Energy Consumption (TEC) = PEC + IEC
Where:
- Processing Energy Consumption (PEC) = Σ(Pj * Ti) / 1000
- Idle Energy Consumption (IEC) = 0% utilization consumption as per server
The power consumption of a data center varies depending on its utilization level[16]. Here’s a general overview of power consumption estimates for data centers at different utilization levels:
High Utilization:
At high utilization levels, when the data center’s servers and infrastructure[15] are running close to their maximum capacity, power consumption is typically at its peak.
The power consumption in a data center at high utilization is primarily driven by the energy consumed by servers, cooling systems, networking equipment, and other supporting infrastructure.
Cooling systems, in particular, may require more energy to maintain optimal operating temperatures when servers are running at full capacity.
Power Usage Effectiveness (PUE), which measures the ratio of total power consumed by the data center to the power consumed by IT equipment, tends to be lower at high utilization levels due to more efficient use of resources.
Low Utilization:
At low utilization levels, when the data center is operating well below its maximum capacity, power consumption is relatively lower compared to high utilization scenarios.
However, even at low utilization, data centers typically consume a significant amount of power due to the overhead associated with maintaining infrastructure readiness and availability.
Cooling systems may still require substantial energy to maintain optimal environmental conditions within the data center facility, even when server loads are minimal.
PUE may be higher at low utilization levels due to the relatively higher proportion of energy consumed by supporting infrastructure compared to IT equipment.
Medium Utilization:
At medium utilization levels, power consumption falls between the extremes of high and low utilization.
Power consumption in a data center at medium utilization is influenced by a combination of factors, including the number of active servers, workload distribution, and efficiency of cooling and power distribution systems.
The efficiency of the data center’s infrastructure and operational practices can have a significant impact on power consumption at medium utilization levels.
PUE values at medium utilization may vary depending on the effectiveness of energy management practices and resource allocation strategies.
To estimate the power consumption of used servers like the HP ProLiant G4, G5, and ML350 Gen11, we can provide some general guidelines based on their specifications. However, it’s important to note that actual power consumption can vary based on factors such as server configuration, workload, and environmental conditions. Here’s a rough estimation of power consumption for each server model:









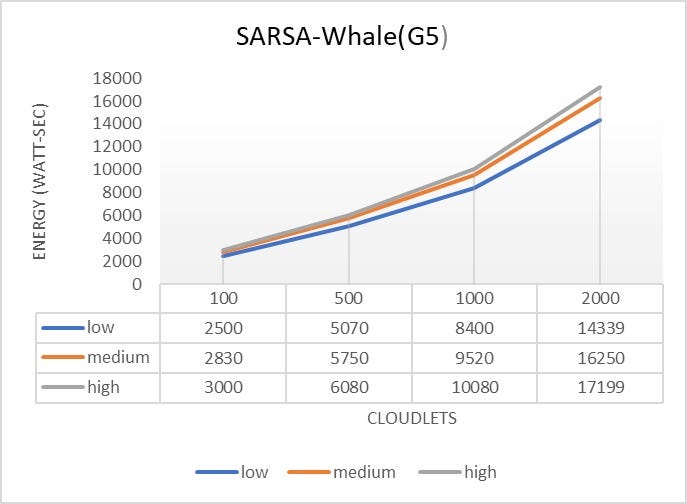
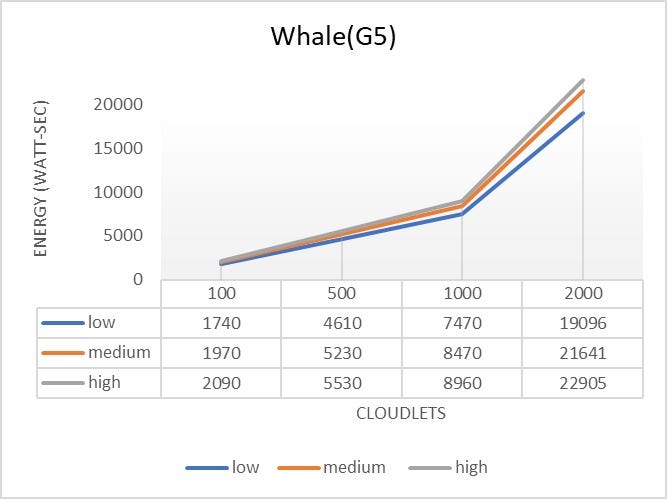
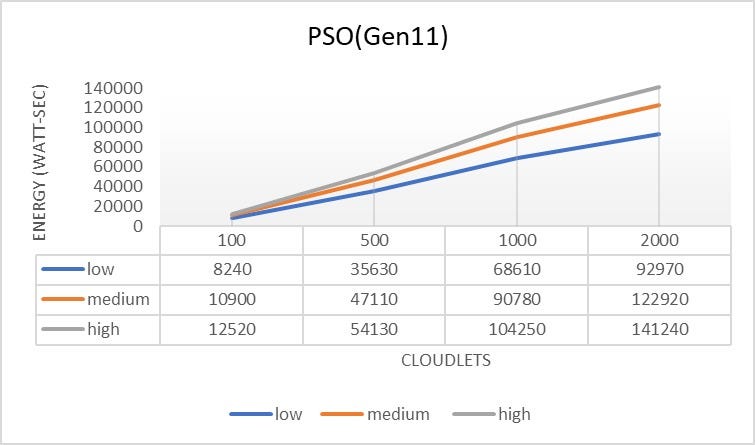
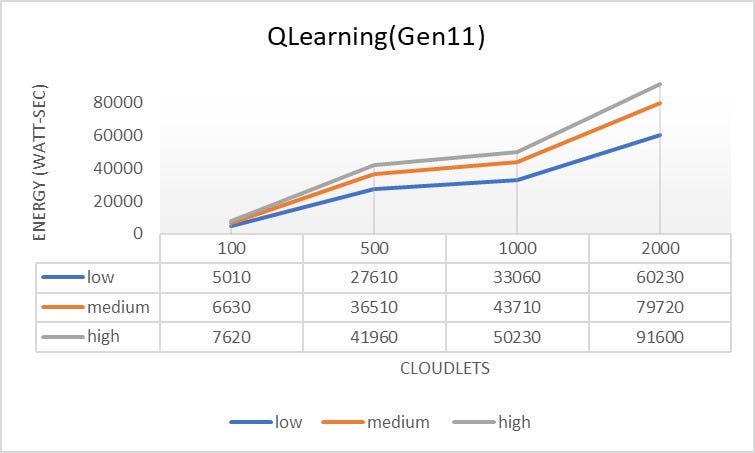
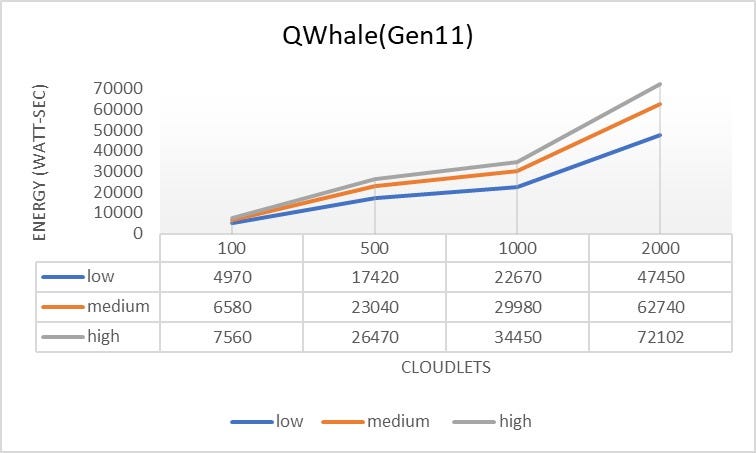
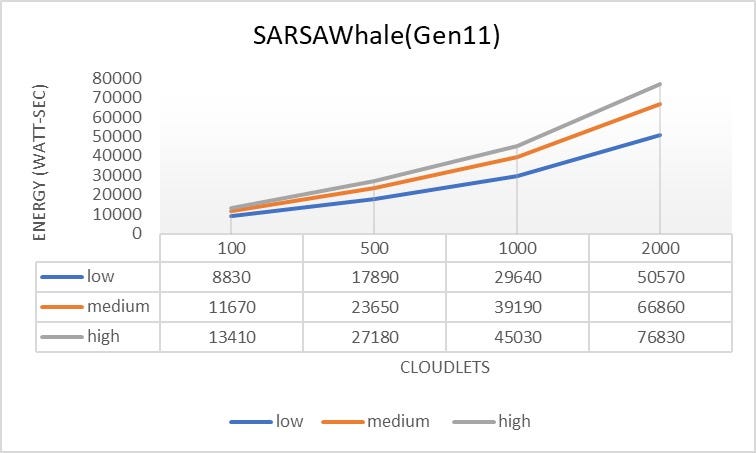
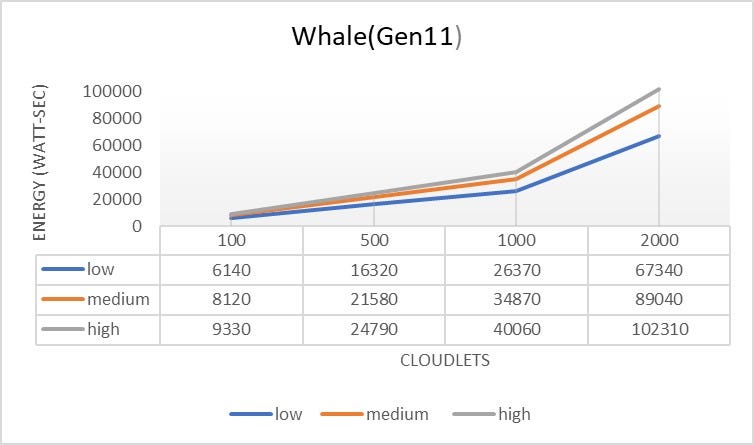
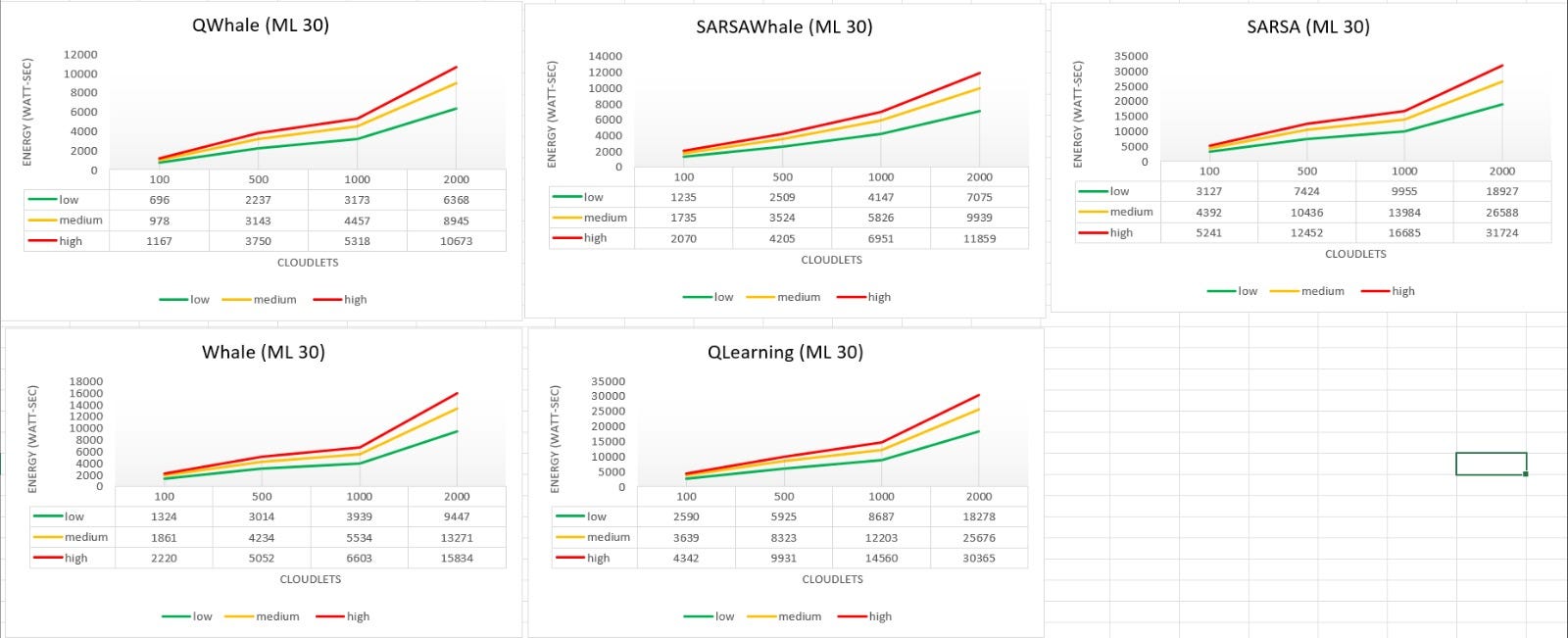

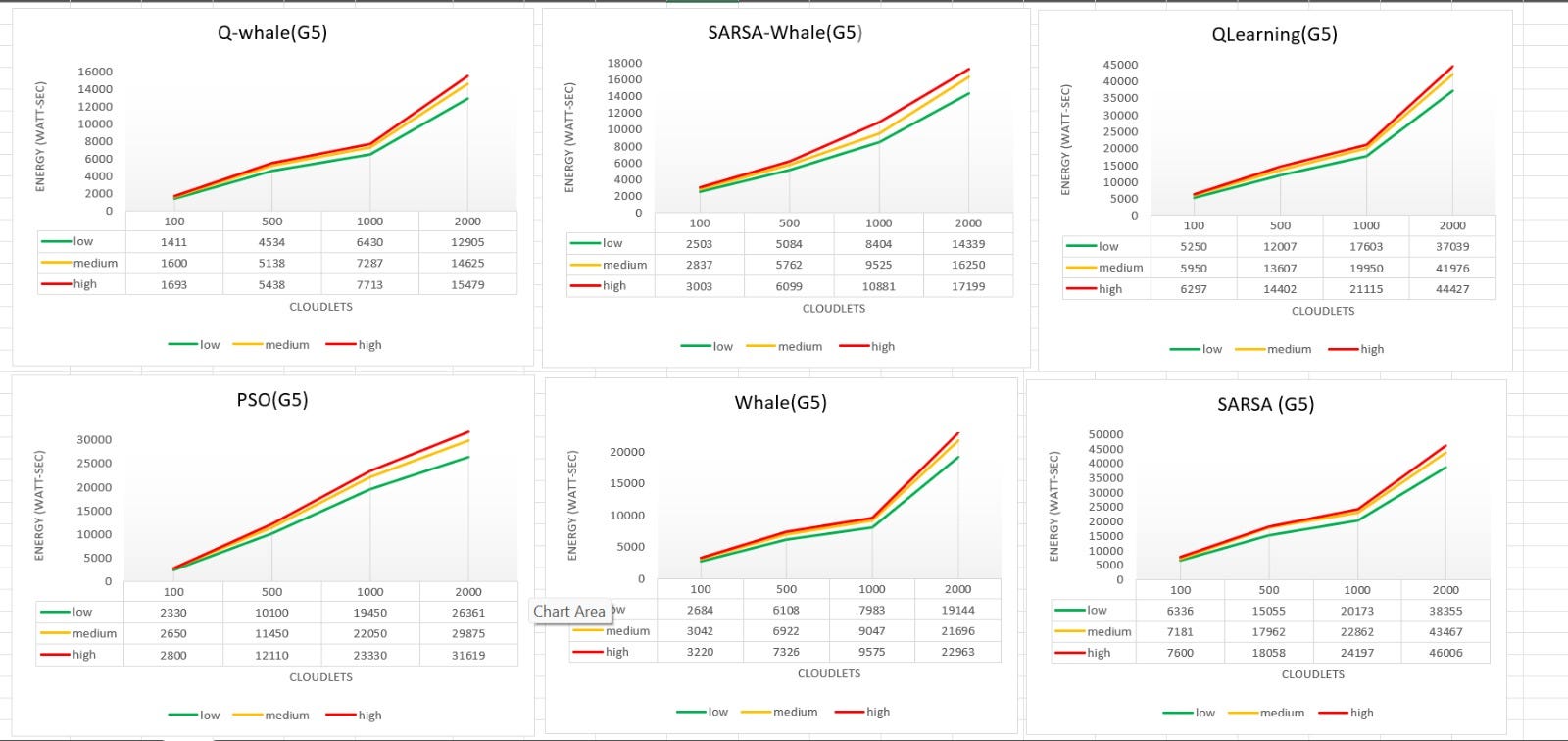





- The Qwhale algorithm consistently demonstrates the lowest energy consumption across all task counts.
- For 100 tasks, Qwhale consumes 1568 watt-seconds, which is significantly lower compared to the next best SARSawhale at 2781 watt-seconds and substantially lower than Q-learning and SARSA, which consume 5832 and 7039 watt-seconds, respectively.
- As the number of tasks increases to 500, 1000, and 2000, Qwhale maintains its efficiency with energy consumption values of 5036, 7143, and 14336 watt-seconds, respectively. This trend highlights the scalability and efficiency of Qwhale in handling larger workloads.
Comparison with Other Algorithms:
- SARSawhale shows the second-best performance but still consumes more energy than Qwhale, particularly noticeable as the task count increases (5648 watt-seconds for 500 tasks, 9603 for 1000 tasks, and 15929 for 2000 tasks).
- Traditional Q-learning and SARSA algorithms exhibit much higher energy consumption, with Q-learning peaking at 41147 watt-seconds and SARSA at 42609 watt-seconds for 2000 tasks. These results underscore the inefficiency of these methods in energy management compared to Qwhale.
- The Whale algorithm, while better than Q-learning and SARSA, still consumes considerably more energy than Qwhale, especially as task volume grows (21267 watt-seconds for 2000 tasks).
The Qwhale algorithm offers significant improvements in energy consumption for task scheduling in cloud computing environments. Its hybrid approach effectively combines Q-learning with the Whale Optimization Algorithm, leading to enhanced efficiency and lower energy use. This makes Qwhale particularly suitable for large-scale data centers where energy consumption is a critical factor. The consistent performance of Qwhale across various task loads demonstrates its scalability and robustness, marking it as a superior choice for modern cloud resource management.
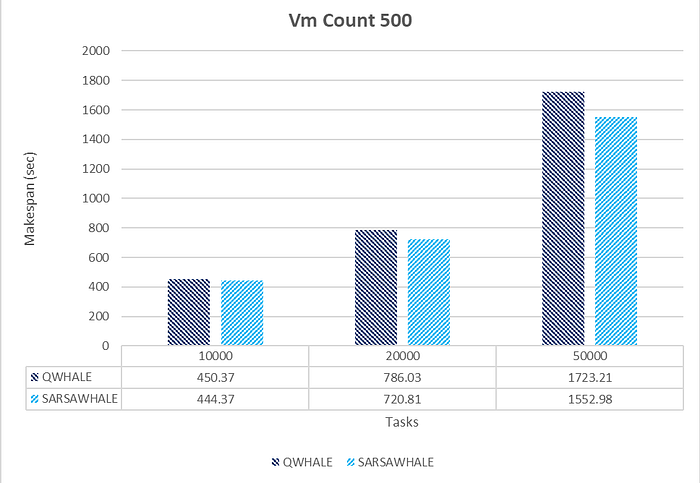
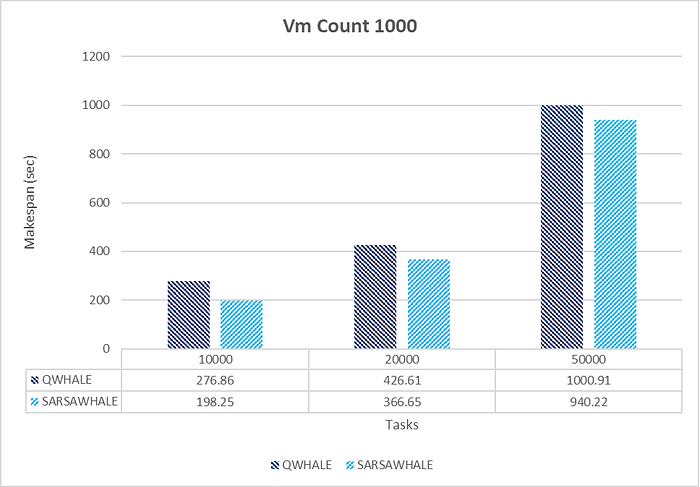
SARSAWhale shows better efficiency and scalability compared to QWhale as the number of tasks increases. The performance gap between the two algorithms narrows as the task count increases, but SARSAWhale still maintains a consistent edge.
The superior performance of SARSAWhale under high load conditions can be attributed to its reinforcement learning-based approach, specifically the SARSA (State-Action-Reward-State-Action) algorithm. This method enables SARSAWhale to dynamically adapt to changing conditions and optimize decision-making processes based on current states and anticipated rewards. Unlike static algorithms, SARSAWhale continuously evaluates actions not only based on the present state but also with consideration for future states, leading to more informed and proactive resource allocation. The algorithm’s capability to fine-tune its performance through ongoing feedback from the environment allows for efficient optimization of resource utilization. This adaptability and continuous learning enhance SARSAWhale’s scalability, making it particularly effective in managing increased workloads. In high load scenarios, where task arrival rates and resource demands are highly variable, SARSAWhale’s robust approach ensures efficient handling and better overall system throughput. Thus, SARSAWhale’s advanced adaptive mechanisms and resource management strategies result in significant performance improvements over traditional algorithms, especially as the number of tasks increases.
Conclusion
In conclusion, the integration of Q-learning and SARSA with the Whale Optimization Algorithm (WOA) has demonstrated significant improvements in solving complex optimization problems compared to conventional WOA and other benchmark algorithms. Our integrated variants consistently outperformed across various instances, achieving optimal solutions in several cases and demonstrating competitive performance close to optimal solutions on average.
Moreover, these integrated approaches streamlined the optimization process, significantly reducing tuning times. Detailed analysis of exploration and exploitation graphs revealed consistent convergence patterns with smaller variations and occurrences in our integrated variants, indicating potential for enhanced problem-solving capabilities.
Looking ahead, further validation and parameterization of results obtained from exploration and exploitation graphs are essential. Standardized metrics for comparison and incorporation into reinforcement learning agents’ learning processes hold promise for advancing the optimization capabilities of metaheuristic algorithms. Overall, these findings underscore the potential of integrating reinforcement learning techniques with metaheuristic algorithms for effectively tackling complex optimization challenges.
In addition to the current advancements, future endeavors should explore the potential of leveraging SARSA’s capability to store experiences for further improving the performance of the integrated SARSA Whale Optimization Algorithm (WOA). By incorporating this feature, the SARSA WOA variant could effectively learn from past experiences, enabling it to adapt more efficiently to varying optimization landscapes. This iterative process of learning and adaptation holds promise for enhancing the robustness and effectiveness of the SARSA-integrated WOA in solving complex optimization problems. Furthermore, continued research into parameterization of results obtained from exploration and exploitation graphs will be crucial in providing a standardized metric for comparison and further advancing the optimization capabilities of metaheuristic algorithms. Overall, these future directions highlight the potential for continuous refinement and improvement of SARSA-integrated WOA, ultimately contributing to more efficient and effective solutions for challenging optimization tasks.
References & Citations
1. Shaw, R., Howley, E., & Barrett, E. (2022, July 1). Applying Reinforcement Learning towards automating energy efficient virtual machine consolidation in cloud data centers. Information Systems. https://doi.org/10.1016/j.is.2021.101722
2. Hassan, A., Abdullah, S., Zamli, K. Z., & Razali, R. (2023, September 18). Q-learning whale optimization algorithm for test suite generation with constraints support. Neural Computing & Applications. Q-learning whale optimization algorithm for test suite … — Springer
3. Li, Y., Wang, H., Fan, J., & Geng, Y. (2022, December 27). A novel Q-learning algorithm based on improved whale optimization algorithm for path planning. PloS One. A novel Q-learning algorithm based on improved whale … — PLOS
4. Natesan, G., & Chokkalingam, A. (2019, October 17). Multi-Objective Task Scheduling Using Hybrid Whale Genetic Optimization Algorithm in Heterogeneous Computing Environment. Wireless Personal Communications. Multi-Objective Task Scheduling Using Hybrid Whale Genetic … — Springer
5. Arvindhan, M., & Dhanaraj, R. K. (2023, November 6). Dynamic Q-Learning-Based Optimized Load Balancing Technique in Cloud. Journal of Mobile Information Systems. https://doi.org/10.1155/2023/7250267
6. Du, Z., Peng, C., Yoshinaga, T., & Wu, C. (2023, July 28). A Q-Learning-Based Load Balancing Method for Real-Time Task Processing in Edge-Cloud Networks. Electronics. https://doi.org/10.3390/electronics12153254
7. Luo, J., Chen, H., Heidari, A. A., Xu, Y., Zhang, Q., & Li, C. (2019, September 1). Multi-strategy boosted mutative whale-inspired optimization approaches. Applied Mathematical Modelling. https://doi.org/10.1016/j.apm.2019.03.046
8. Sharma, S., & Pandey, N. K. (2024, February 1). Multi-Faceted Job Scheduling Optimization Using Q-learning With ABC In Cloud Environment. International Journal of Computing and Digital System/International Journal of Computing and Digital Systems. https://doi.org/10.12785/ijcds/150142
9. Hamad, Q. S., Samma, H., & Suandi, S. A. (2023, January 5). Q-Learning based Metaheuristic Optimization Algorithms: A short review and perspectives. Research Square (Research Square). https://doi.org/10.21203/rs.3.rs-1950095/v1
10. Xiu, X., Li, J., Long, Y., & Wu, W. (2023, May 10). MRLCC: an adaptive cloud task scheduling method based on meta reinforcement learning. Journal of Cloud Computing. https://doi.org/10.1186/s13677-023-00440-8
11. Ding, D., Fan, X., Zhao, Y., Kang, K., Yin, Q., & Zeng, J. (2020, July 1). Q-learning based dynamic task scheduling for energy-efficient cloud computing. Future Generation Computer Systems. https://doi.org/10.1016/j.future.2020.02.018
12. Tran, C., Bui, T., & Pham, T. D. (2022, January 29). Virtual machine migration policy for multi-tier application in cloud computing based on Q-learning algorithm. Computing. https://doi.org/10.1007/s00607-021-01047-0
13. Assia, S., Abbassi, I. E., Barkany, A. E., Darcherif, M., & Biyaali, A. E. (2020, April 14). Green Scheduling of Jobs and Flexible Periods of Maintenance in a Two-Machine Flowshop to Minimize Makespan, a Measure of Service Level and Total Energy Consumption. Advances in Operations Research. https://doi.org/10.1155/2020/9732563
14. Xing, L., Li, J., Cai, Z., & Hou, F. (2023, April 30). Evolutionary Optimization of Energy Consumption and Makespan of Workflow Execution in Clouds. Mathematics. https://doi.org/10.3390/math11092126
15. Trivedi, D. K. S. S. A. M. C. (2021, July 26). Energy Aware Scheduling of Tasks in Cloud environment. https://www.tojqi.net/index.php/journal/article/view/3376
16. Pawlish, M., Varde, A. S., & Robila, S. A. (2012, June 1). Analyzing utilization rates in data centers for optimizing energy management. https://doi.org/10.1109/igcc.2012.6322248
17. Shaw, R., Howley, E., & Barrett, E. (2018, December 1). A Predictive Anti-Correlated Virtual Machine Placement Algorithm for Green Cloud Computing. https://doi.org/10.1109/ucc.2018.00035
18. Naz, I., Naaz, S., Agarwal, P., Alankar, B., Siddiqui, F., & Ali, J. (2023, May 5). A Genetic Algorithm-Based Virtual Machine Allocation Policy for Load Balancing Using Actual Asymmetric Workload Traces. Symmetry. https://doi.org/10.3390/sym15051025
19. Mangalampalli, S., Karri, G. R., & Köse, U. (2023, February 1). Multi objective trust aware task scheduling algorithm in cloud computing using whale optimization. Journal of King Saud University. Computer and Information Sciences/Maǧalaẗ Ǧamʼaẗ Al-malīk Saud : Ùlm Al-ḥasib Wa Al-maʼlumat. https://doi.org/10.1016/j.jksuci.2023.01.016

